
介绍
高性能数据访问层需要大量有关数据库内部,JDBC,JPA,Hibernate的知识,本文总结了一些可用于优化企业应用程序的最重要技术。
1. SQL语句记录
如果您使用的是代表您生成语句的框架,则应始终验证每个语句的有效性和效率。测试时断言机制甚至更好,因为即使在提交代码之前,您也可以捕获N + 1个查询问题。2.连接管理
数据库连接很昂贵,因此您应始终使用连接池机制。由于连接数由底层数据库集群的功能提供,因此您需要尽快释放连接。
在性能调优中,您始终必须进行测量,并且设置正确的池大小也没有区别。即使在将应用程序部署到生产环境中之后,像FlexyPool这样的工具也可以帮助您找到合适的大小。
3. JDBC批处理
JDBC批处理允许我们在单个数据库往返中发送多个SQL语句。在驱动程序和数据库方面,性能提升都很重要。 PreparedStatements非常适合批处理,一些数据库系统(例如Oracle)仅支持仅对预准备语句进行批处理。由于JDBC为批处理定义了一个独特的API(例如PreparedStatement.addBatch和PreparedStatement.executeBatch),如果您手动生成语句,那么您应该从一开始就知道是否应该使用批处理。使用Hibernate,您可以使用单个配置切换到批处理。
Hibernate 5.2提供了会话级批处理,因此在这方面更加灵活。
4.语句缓存
语句缓存是您可以轻松利用的最不为人知的性能优化之一。根据底层的JDBC驱动程序,您可以在客户端(驱动程序)或数据库端(语法树甚至执行计划)缓存PreparedStatements。5. Hibernate标识符
使用Hibernate时,IDENTITY生成器不是一个好选择,因为它禁用了JDBC批处理。
TABLE生成器甚至更糟,因为它使用单独的事务来获取新标识符,这会对底层事务日志以及连接池施加压力,因为每次我们需要新标识符时都需要单独的连接。
SEQUENCE是正确的选择,甚至SQL Server也支持自2012版本。对于SEQUENCE标识符,Hibernate长期以来一直提供诸如池化或池化等优化器,这可以减少获取新实体标识符值所需的数据库往返次数。
6.选择正确的列类型
您应始终在数据库端使用正确的列类型。列类型越紧凑,数据库工作集中可以容纳的条目越多,索引将更好地适应内存。为此,您应该利用特定于数据库的类型(例如,PostgreSQL中的IPv4地址的inet),特别是因为Hibernate在实现新的自定义类型时非常灵活。7.关系
Hibernate带有许多关系映射类型,但并非所有关系映射类型在效率方面都是相同的。
关系

应避免使用单向集合和@ManyToMany列表。如果您确实需要使用实体集合,则首选双向@OneToMany关联。对于@ManyToMany关系,使用Set(s),因为它们在这种情况下更有效,或者只是映射链接的多对多表并将@ManyToMany关系转换为两个双向@OneToMany关联。
但是,与查询不同,集合的灵活性较低,因为它们不能轻易分页,这意味着当子关联的数量相当高时,我们无法使用它们。因此,您应该始终询问是否真的需要集合。在许多情况下,实体查询可能是更好的选择。
8.继承
在继承方面,面向对象语言和关系数据库之间的阻抗不匹配变得更加明显。 JPA提供了SINGLE_TABLE,JOINED和TABLE_PER_CLASS来处理继承映射,并且这些策略中的每一个都有优点和缺点。SINGLE_TABLE在SQL语句方面表现最好,但由于我们不能使用NOT NULL约束,因此我们在数据完整性方面失败了。
JOINED解决了数据完整性限制,同时提供了更复杂的语句。只要您不对基类型使用多态查询或@OneToMany关联,此策略就可以了。它的真正力量来自于数据访问层一侧的策略模式支持的多态@ManyToOne关联。
应避免使用TABLE_PER_CLASS,因为它不会生成有效的SQL语句。
9.持久性上下文大小
使用JPA和Hibernate时,应始终注意持久化上下文大小。出于这个原因,你绝不应该使用大量的托管实体来臃肿它。通过限制托管实体的数量,我们获得了更好的内存管理,并且默认的脏检查机制也将更加高效。10.只获取必要的东西
获取过多数据可能是数据访问层性能问题的首要原因。一个问题是实体查询是专门使用的,即使对于只读投影也是如此。DTO投影更适合于获取自定义视图,而实体应仅在业务流程需要修改它们时获取。
EAGER提取是最糟糕的,你应该避免反模式,如Open-Session in View。
11.缓存
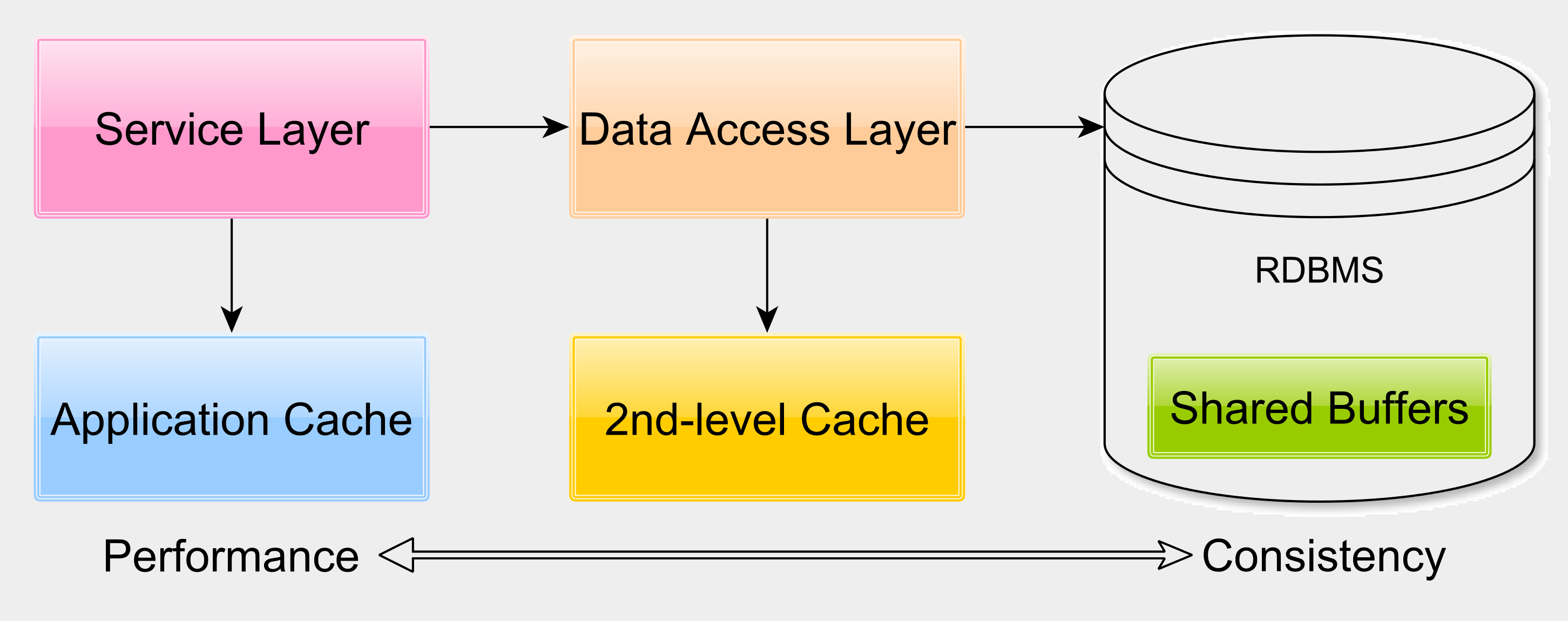
关系数据库系统使用许多内存缓冲区结构来避免磁盘访问。数据库缓存经常被忽视。我们可以通过适当调整数据库引擎来显着缩短响应时间,以便工作集驻留在内存中,并且不会一直从磁盘中获取。
对于许多企业应用程序,应用程序级缓存不是可选的。应用程序级缓存可以缩短响应时间,同时在数据库因维护而关闭或由于某些严重的系统故障而提供只读辅助存储。
二级缓存对于减少读写事务响应时间非常有用,尤其是在主从复制体系结构中。根据应用程序的要求,Hibernate允许您在READ_ONLY,NONSTRICT_READ_WRITE,READ_WRITE和TRANSACTIONAL之间进行选择。
13.释放数据库查询功能
仅仅因为您使用JPA或Hibernate,并不意味着您不应该使用本机查询。您应该利用窗口函数,CTE(公用表表达式),CONNECT BY,PIVOT。这些构造允许您避免获取太多数据,以便稍后在应用程序层中对其进行转换。如果您可以让数据库进行处理,则可以仅获取最终结果,从而节省大量磁盘I / O和网络开销。为避免主节点过载,您可以使用数据库复制并使多个Slave节点可用,以便在Slave上而不是在Master上执行数据密集型任务。
14.向上扩展和向外扩展
关系数据库的确可以很好地扩展。如果Facebook,Twitter,Pinterest或StackOverflow可以扩展其数据库系统,则很有可能将企业应用程序扩展到其特定的业务需求。
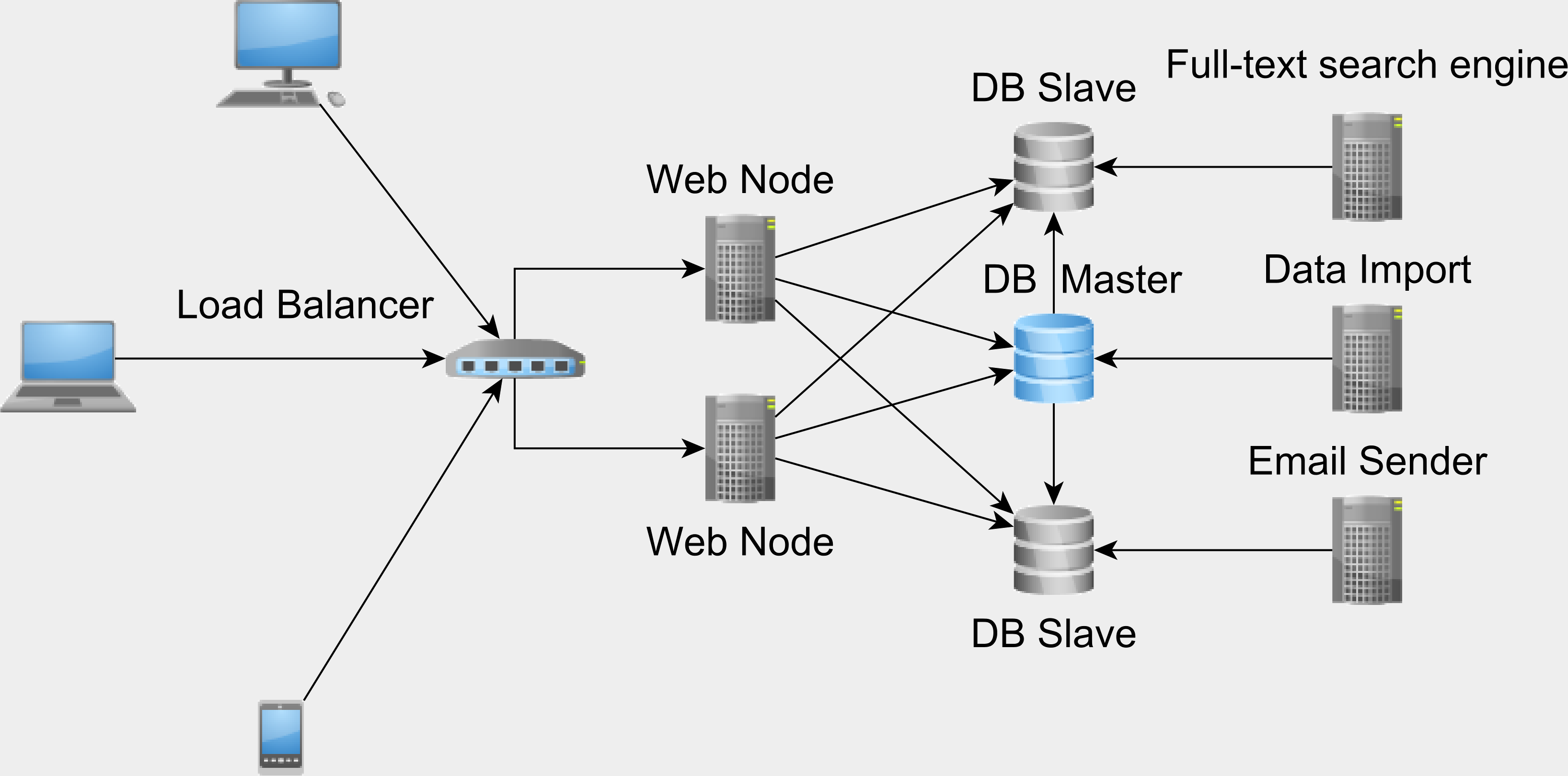
是提高吞吐量的非常好的方法,您应该完全利用这些经过实战考验的体系结构模式来扩展您的企业应用程序。
结论
高性能数据访问层必须与底层数据库系统产生共鸣。 了解关系数据库的内部工作原理以及正在使用的数据访问框架可以使高性能企业应用程序与几乎无法爬行的应用程序之间产生差异。
您可以采取许多措施来改善数据访问层的性能,我只是在这里赘述。
如果您想要阅读有关此特定主题的更多信息,您还应该查看我的书籍。 这本书有450多页,非常详细地解释了所有这些概念。注:文中涉及的链接不再补充。